Visuelle Inspektion
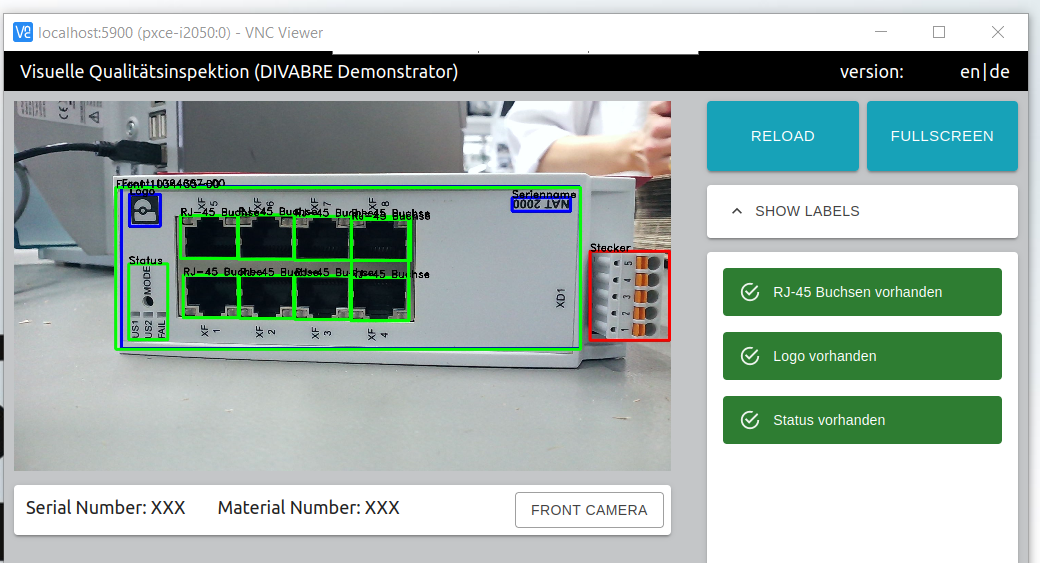
Im Schwerpunkt „Visuelle Inspektion“ widmen wir uns der Anwendung von Deep Learning und Computer Vision zur Unterstützung industrieller Inspektionsprozesse. Unser Forschungsansatz ist es, neueste Methoden aus dem Stand der KI-Forschung zu adaptieren und neue Lösungsansätze zu entwickeln, um visuelle Inspektionen präziser, effizienter und transparenter zu machen.
Datenerzeugung

Für das Training robuster KI-Modelle, werden große Mengen kuratierter Bilddaten benötigt. Viele Modelle setzen daher sogenannte Backbones ein, die auf extrem großen, aber unspezifischen Datensätzen wie ImageNet vortrainiert sind. Für den Transfer auf spezifische Inspektionsszenarien reichen diese Backbones jedoch nicht aus und müssen durch qualitativ hochwertige Bildaufnahmen angereichert werden.
Für diese Anreicherung setzen wir DOME ein -- unserer Lösung für automatisierte Datenerzeugung. Hiermit wird es möglich, innerhalb weniger Sekunden Objekte aus verschiedenen Blickwinkeln zu erfassen. Mit über 1900 einzeln ansteuerbaren LEDs in der Anordnung einer Halbkugel können wir verschiedene Ausleuchtungsszenarien simulieren so wie sie in realen Fertigungsprozessen. Die darauf trainierten KI-Modelle für die Qualitätsinspektion sind robust gegenüber typischen Änderungen des Farbspektrums und ungleichmäßigen Ausleuchtungen mit Schattenwurf.
Qualitätsbewertung und Fehlererkennung

Unser Ziel ist die Entwicklung Methoden zur präzisen Qualitätsbewertung und Fehlererkennung in industriellen Produktionsprozessen auf Basis von Bilddaten. Durch den Einsatz von fortschrittlichen Modellen wie Vision Transformer und Normalizing Flow Verfahren fokussieren wir uns auf die zuverlässige Detektion von Anomalien und die Identifikation von Fehlern.
Umgang mit realen Bedingungen
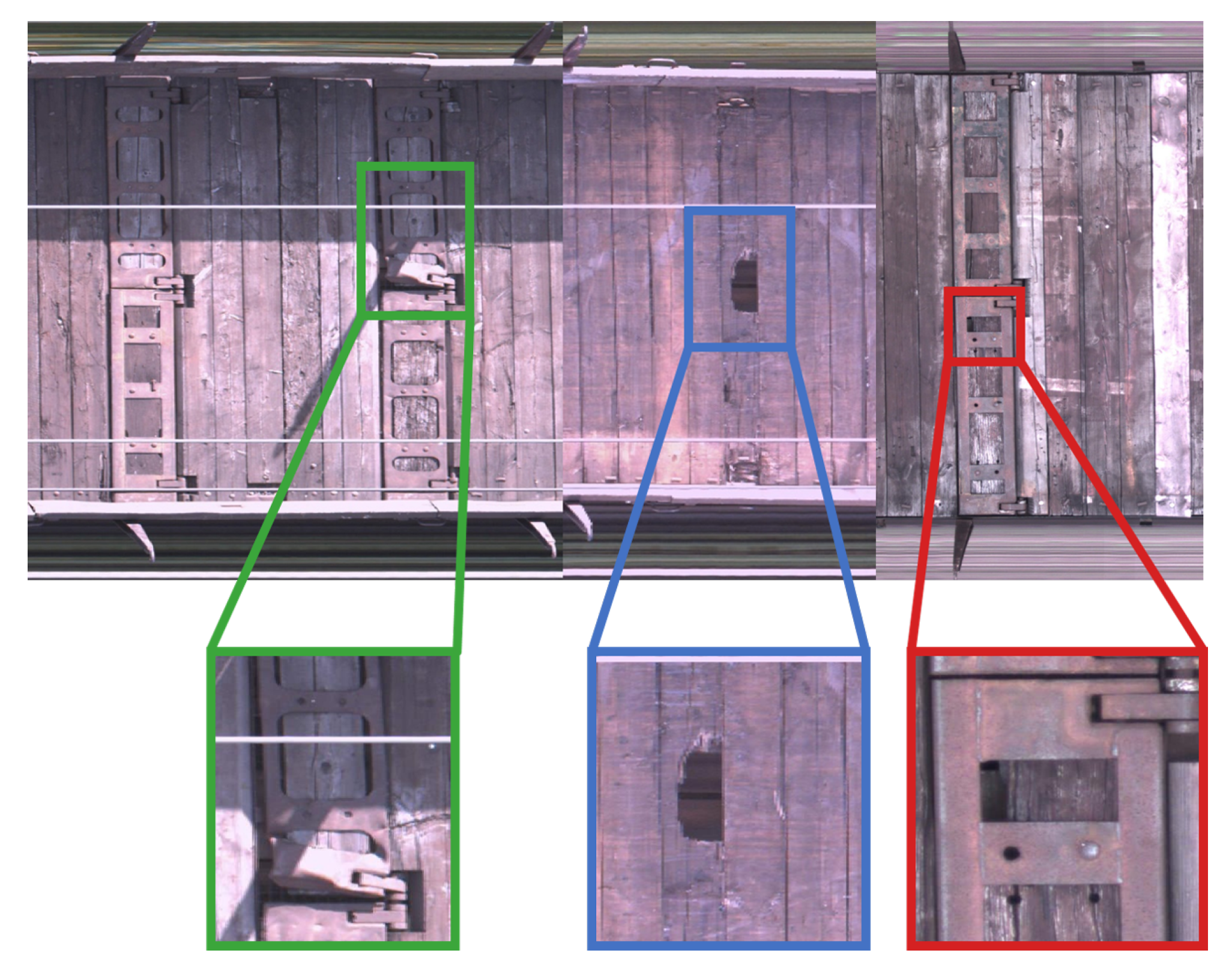
Die Herausforderungen der visuellen Inspektion in realen Produktionsumgebungen erfordern skalierbare und anpassungsfähige Lösungen. Wir entwickeln mehrstufige Modellpipelines, die in der Lage sind, große und hochauflösende Bilddaten effizient zu verarbeiten. Dabei forschen wir an der Generalisierung von Deep Learning-Methoden, um die Modelle gegenüber verschiedenen Umgebungen und Störfaktoren robust zu machen. Ein weiterer Schwerpunkt liegt auf der Erklärbarkeit und Visualisierung der Ergebnisse, um das Vertrauen in die Technologie zu stärken und eine kontinuierliche Optimierung der Modelle zu ermöglichen.