ISWC 2023: Alexander Paulus stellt PLASMA-Publikation auf der Semantic Web-Konferenz in Athen vor
ISWC 2023: Alexander Paulus stellt PLASMA-Publikation auf der Semantic Web-Konferenz in Athen vor
Die Forschung zu heterogenen Daten und deren Zusammenführung ist ein kontinuierlicher Prozess, der im Laufe der Zeit an Bedeutung gewonnen hat. Die Notwendigkeit, verschiedene Datenquellen miteinander zu verknüpfen und zu integrieren, besteht seit langem. Die zunehmende Verfügbarkeit und Nutzung unterschiedlicher Datenquellen hat jedoch in den letzten Jahrzehnten zu einem verstärkten Fokus auf die Erforschung und Entwicklung von Methoden zur Verarbeitung heterogener Daten geführt. In den 1990er Jahren begannen Forscher, sich verstärkt mit der Integration heterogener Datenquellen zu beschäftigen. Dabei wurden verschiedene Ansätze und Techniken entwickelt, um den Herausforderungen bei der Verarbeitung, Integration und Analyse heterogener Daten zu begegnen. Mit den Fortschritten in der Datenbanktechnologie, der Entwicklung von Standards für den Datenaustausch und der zunehmenden Bedeutung von Big Data und Datenintegration hat sich die Forschung zu heterogenen Datenquellen weiterentwickelt. Heute ist dies ein aktives und dynamisches Forschungsgebiet. Ein Forschungsansatz ist das semantische Datenmanagement.
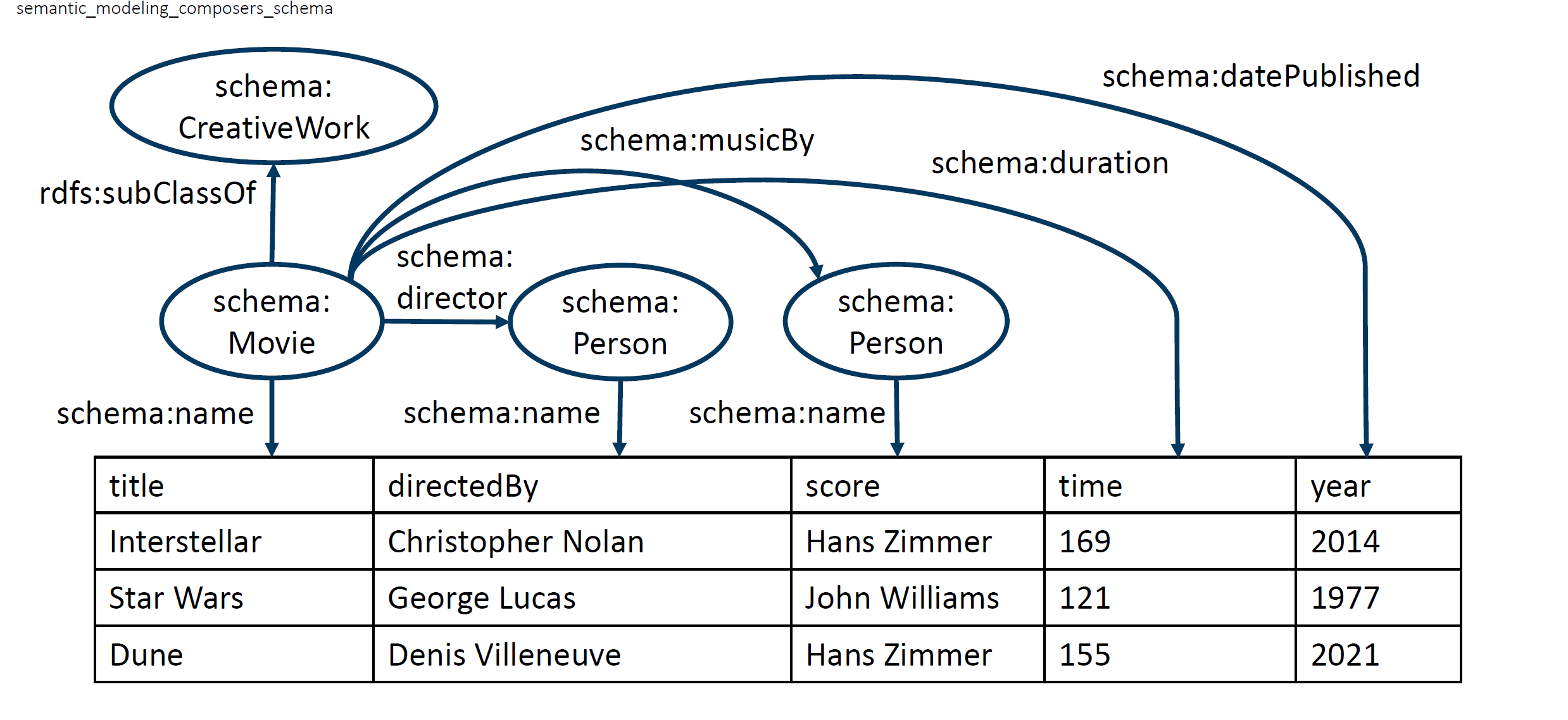
Im Bereich des semantischen Datenmanagements hat sich die Verwendung gemeinsamer Konzeptualisierungen wie Wissensgraphen oder Ontologien als besonders effektiv erwiesen, um heterogene Datenquellen effizient zu verwalten und zu konsolidieren. Beispielsweise werden auf Basis einer bestehenden Ontologie alle Datenattribute der vorhandenen Datensätze auf Klassen dieser Ontologie abgebildet. Dieser Vorgang wird als semantisches Labeling bezeichnet und ermöglicht bereits die Interpretation der Datenattribute im Rahmen der Ontologie. Um eine feingranulare Beschreibung der Daten zu erhalten, ist die Erstellung eines semantischen Modells der etablierte Ansatz.
Die manuelle Erstellung semantischer Modelle erfordert jedoch Fachwissen und ist zeitaufwändig. Heute gibt es bereits verschiedene automatisierte und halbautomatisierte Ansätze zur Unterstützung der Erstellung eines semantischen Modells. Dabei werden verschiedene Informationen aus und über die zu annotierenden Datensätze (Label, Daten, Metadaten) verwendet, um semantische Labels und vollständige semantische Modelle zu erstellen. Automatisierte Ansätze sind jedoch aus verschiedenen Gründen in ihrer Anwendbarkeit in realen Szenarien eingeschränkt und erfordern daher eine manuelle Nachbearbeitung. Dieser Nachbearbeitungsprozess wird als Semantic Refinement bezeichnet. Dies geschieht in der Regel durch Domänenexperten, d.h. Anwender, die die Daten sehr gut kennen, aber in der Regel keine oder nur geringe Kenntnisse über semantische Technologien haben.
An diesen beiden Herausforderungen setzt unsere Forschung an. Unsere Forschung konzentriert sich sowohl auf die verbesserte automatische Generierung von semantischen Labels und Modellen mittels maschineller Lernverfahren als auch auf die effiziente und semi-automatisierte Nachbearbeitung (z.B. durch Empfehlungssysteme) von automatisch generierten semantischen Modellen. Dabei verfolgen wir das übergeordnete Ziel, semantische Modellierung praxistauglich und skalierbar zu machen.
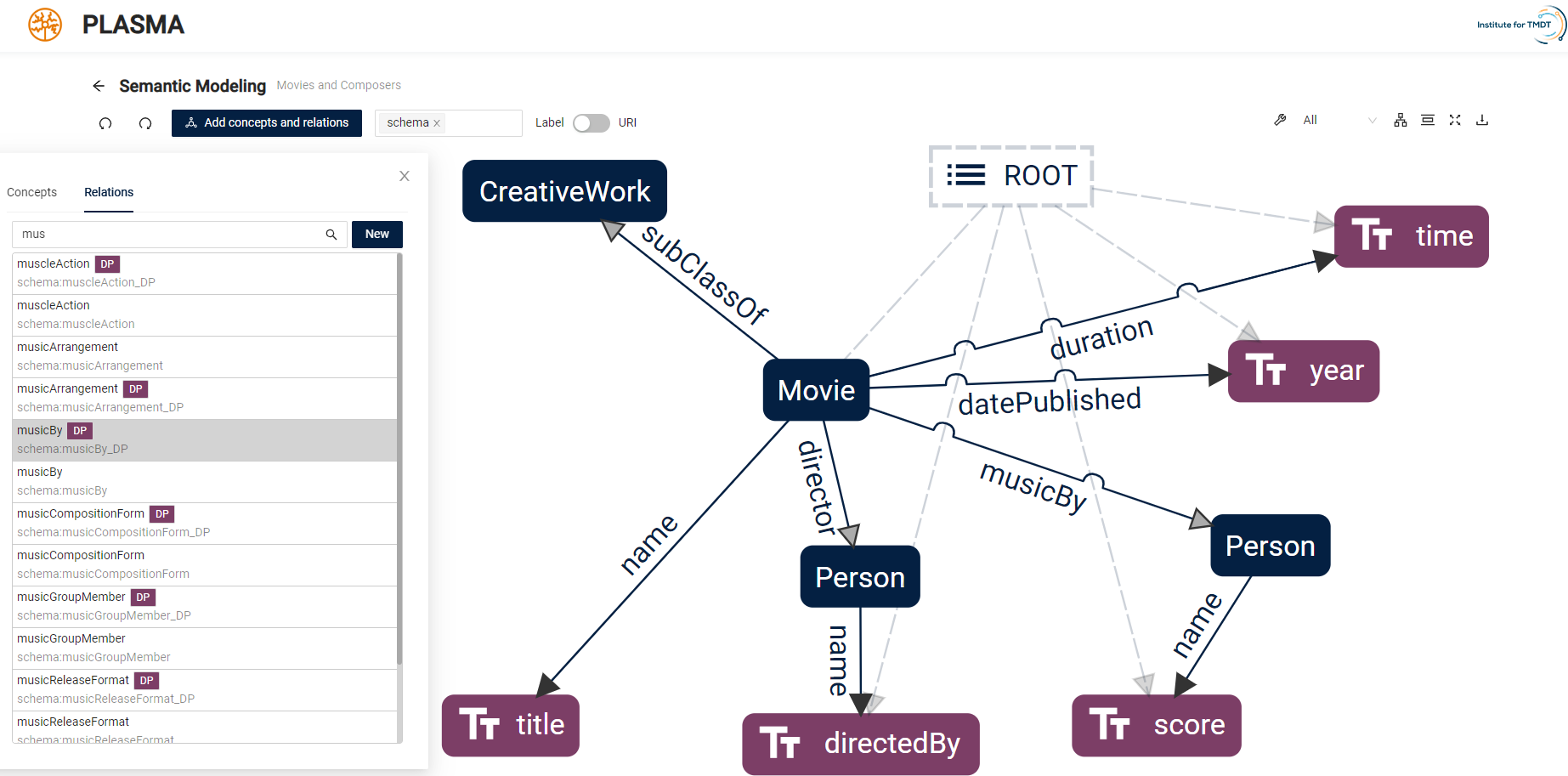
Ein zentrales Ergebnis unserer Forschung ist das PLASMA Framework. PLASMA ist ein Werkzeug zur Erstellung und Bearbeitung semantischer Modelle, das sich vor allem an fachfremde Nutzer richtet. Die erste Version dieser semantischen Modellierungsplattform wurde 2021 von uns vorgestellt und kontinuierlich weiterentwickelt. PLASMA bietet eine einfach zu bedienende grafische Benutzeroberfläche, um die Einstiegshürde für Nutzer ohne Erfahrung mit semantischer Modellierung zu senken. PLASMA wickelt alle Interaktionen im Zusammenhang mit dem Modellierungsprozess ab, verwaltet eigene Ontologien und einen Wissensgraphen und ist in der Lage, Eingabedaten zu analysieren, um deren Schema zu identifizieren. Darüber hinaus ermöglichen die von PLASMA bereitgestellten Schnittstellen und Bibliotheken die direkte Integration in Datenräume. Durch die zugrundeliegende Microservice-Architektur können zudem verschiedene existierende Ansätze zur automatisierten semantischen Modellierung in den Prozess integriert werden. PLASMA ist Open Source und kann hier getestet werden.
Unsere Forschung findet Anwendung in allen Kontexten, die sich mit semantischem Datenmanagement (Auffinden und Integrieren semantischer Daten) beschäftigen bzw. überall dort, wo Mappings zwischen Konzeptualisierungen und Daten benötigt werden. Dies sind heute insbesondere die Bereiche rund um Datenräume (Dataspaces), den Aufbau von Wissensgraphen sowie das Datenmanagement nach den FAIR-Prinzipien.
ISBN: 978-1-6654-8263-9
ISBN: 9781450394192
ISBN: 9781450394192
ISBN: 9781450392365
Weitere Infos über #UniWuppertal: